
生成AIの活用、もう一歩踏み込むために必要な要素とは?
2022年11月にリリースされた大規模言語モデルであるChatGPTは、日本では2023年に熱狂という形で受け入れられました。メールなどの文章作成や議事録の要約、調べものへの使用、アイデア出しの壁打ち相手など、生身のアシスタントがいるような驚きがあったかと思います。
一方で、汎用的過ぎて自社に特化し深堀りした内容にアジャストさせることには、まだまだ成長途上であることも、ご存じのとおりかと思います。 自社の仕組みに合わせた形で生成AIを用いて効率化を目指すことは自然な流れです。業務効率化という目的だけでも、これができるなら、もっとあんなこともできるのではないか、など思案を巡らせているのではないでしょうか?
生成AIを使いやすくするツールなども出そろってきており、2024年は成熟していく流れのなかで、自社の活用方法においても深く踏み込むことが、求められていくことになります。
もう一歩踏み込んで、生成AIを使いこなすには
ChatGPT/Azure OpenAIなどの生成AIの導入は、機密のガードや認証、ログなど、社内利用するうえで留意する要素はあるとはいえ、ただ使うだけの場合は運用の検討を含め導入のハードルはそれほど高くないものです。もう一段踏み込んだ活用を行うには、どのようにすべきでしょうか?
全体の流れとしては、以下のようになると思われます。
① まずは何をするかの目的と利用上の制約を明確にする
② 実現の可能性検証や実現方針を検討する
③ コスト見積もりや導入定着などの計画を立案する
④ 展開計画に沿った導入の実施と定着へのフォローを実施する
本記事では②の実現方針の例として、業務効率化を目的に自社内のナレッジを検索・共有するケースを考えてみたいと思います。具体的には前提として、自社内のナレッジがファイルサーバーやオンラインストレージを置き場として、ExcelまたはPowerPointのファイルで配置されていることとします。
生成AIの活用におけるエントリーモデル
今回の目的での生成AIの活用パターンは、4パターンほどになります。まずは難易度が低く、生成AI初期導入時期として、2つのパターンを紹介します。
パターン1:
「利用ユーザーと生成AIの間にLANG Chainなどを使って自社内ナレッジのデータの利用の幅を広げる」
RAG(Retrieval-Augmented Generation:検索拡張生成)構成と呼ばれるものになります。あくまで自社内ナレッジを検索するものとなるので、対話の回答精度は検索結果の範囲内となります。ファインチューニング(既に学習済みのモデルに新たなデータを使用して再学習させ、より意図どおりの回答精度とする)を行わないので、ファインチューニングに必要な料金はかかりません。
機械学習エンジニアは不要ですが、Lang Chainなどの検索拡張を行うプロダクトの理解、導入、設定は必要です。また自社内ナレッジの検索についても理解、検索ツール設定が必要となります。
パターン2:
「自社内ナレッジからデータを抽出し、ChatGPT/Azure OpenAIなどの生成AIサービス側が用意した仕組みでファインチューニングを実施する」
自社内ナレッジからデータを抽出しChatGPT/Azure OpenAIにデータを登録、ファインチューニングのコマンドを実行するだけで、自社内ナレッジを踏まえて回答するようになります。自由度は少ないものの、比較的容易に自社内ナレッジの検索・共有が対話形式でできます。なおファインチューニングをどのようなデータ範囲で、どのタイミングで実施するかなどの運用を追加で検討する必要があります。機械学習エンジニアは不要ですが、自社内ナレッジからデータ抽出・加工ができ、ChatGPT/Azure OpenAIのドキュメントをある程度理解し、ファインチューニングのコマンドを実行できるレベルのITエンジニアは必要となります。
2023年11月に発表されたGTPsは、コマンド実行ではなくノーコードでファインチューニング可能です。しかし、本記事執筆時点(2024年10月下旬)では20ファイル以内の制限がありますので、こちらは今後のアップデートに期待となります。
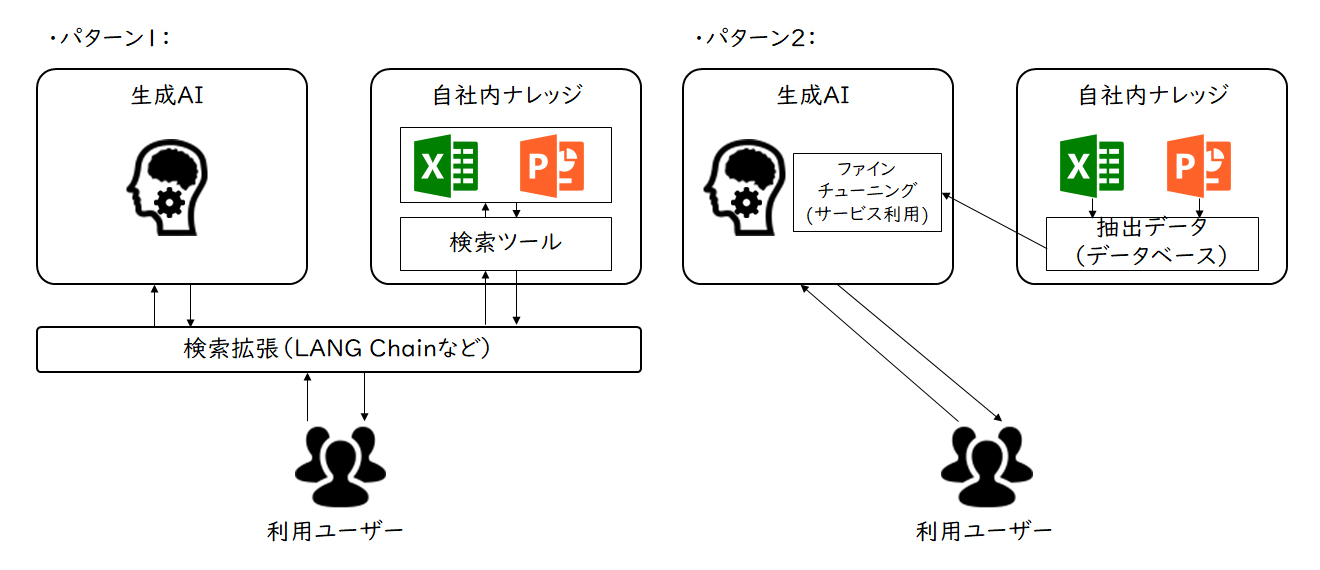
【図1】パターン1、2のシステム概要図
生成AIの活用における高度化モデル
続いてパターン3、4になります。
パターン3:
「オープンな大規模言語モデルをベースに、自社ナレッジからデータを抽出しファインチューニングする」
Hugging faceなどの大規模言語モデルを公開しているWebサイトより、モデルを選定し利用します。(商用利用など権利関係は要確認)自社独自のファインチューニングができるので、より思いどおりのモデルが作成可能となります。自社内のモデルになるので管理も自社となり、モデルの運用を別途考慮する必要があります。またファインチューニングするにあたりGPUが必要となりますので、GPU確保をどのように行うかの課題もあります。なおこのパターンは、モデルの選定や環境の構築・ファインチューニングの実施などに機械学習エンジニアの力が必要となります。
パターン4:
「オープンなコーパス(自然言語の文章を構造化し大規模に集積したもの)をベースに自社内ナレッジのデータを加え、大規模言語モデルを独自生成する」
パターン3と似ていますが、モデルそのものを独自に作成することになりますので、制約なく自社に最もフィットしたものを作成可能となります。パターン3同様に管理が自社となりますので、モデルの運用を別途考慮する必要があります。一からモデルを作成する都合上ファインチューニングよりも多くのGPUが必要となりますので、GPUの確保の課題もあります。当然ながら機械学習エンジニアも必要となります。
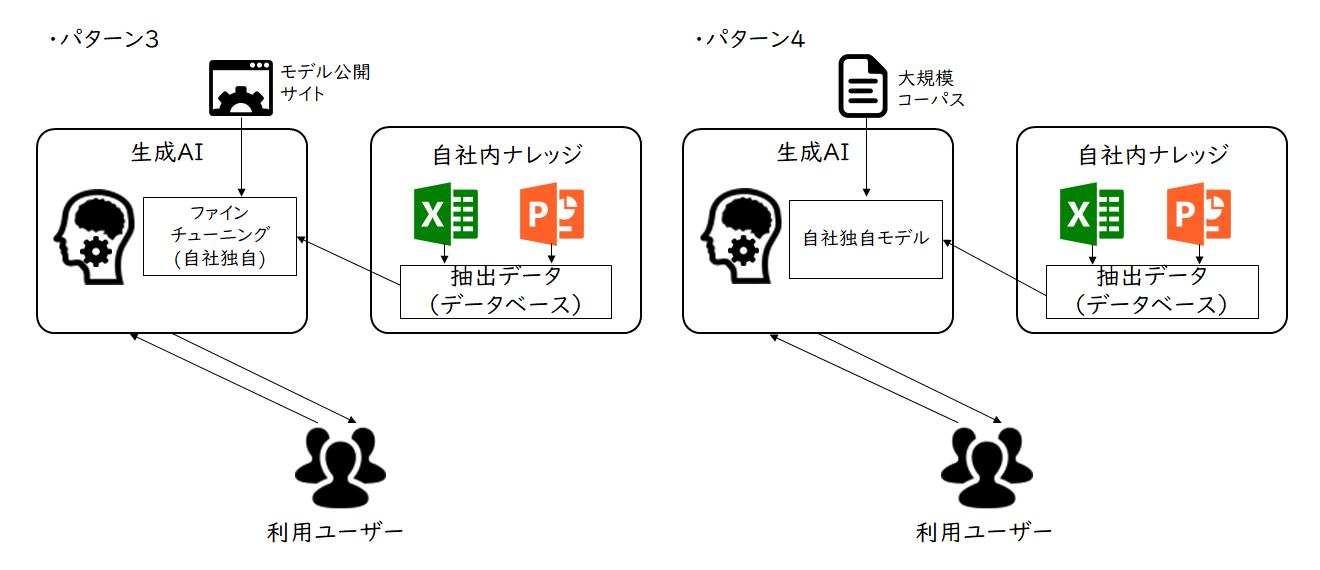
【図2】パターン3、4のシステム概要図
生成AIだけがあっても解決策にはならない
生成AIの活用において、どのパターンを使うかは目的や状況に依存しますが、ハードルの低さからパターン1、2が選択されやすいものとなるかと思います。
GPUやエンジニアなどが必要なパターンもありますが、すべてのパターンで自社内ナレッジのデータを参照・抽出する必要があります。データの量が十分にあり、データの精度や鮮度が高くないと、生成AIから期待した回答が返ってこないことは、容易に想像できると思います。
例えば、目的として「データを活用して競合に差をつけたい」と考えたときに、どれだけ生成AIを自社にフィットするように磨き上げたところで、データの量が十分にありかつ精度や鮮度が保たれている状態、すなわち現時点であっても、データ活用のベースが調えられていることが必要となります。
目的からみれば、データが主役で、生成AIは活用手法の一つでしかないのです。
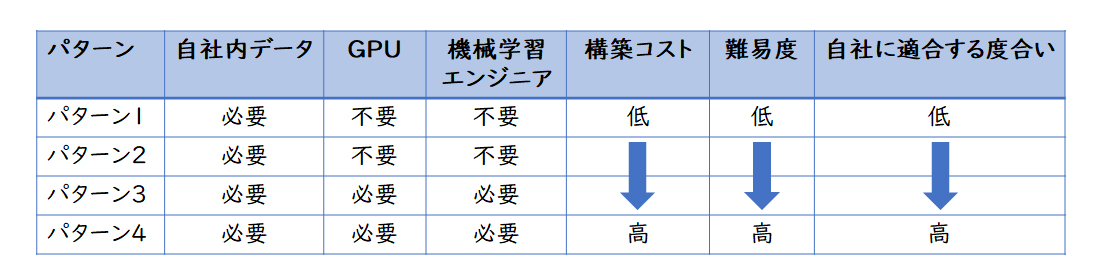
【図3】パターン比較表
生成AIを使う目的はなにか、そのための準備はできていますか?
【図4】よりデータ活用は6割強の企業で進んでいるとのことですが、皆様においては生成AIを使いこなすに足るデータ活用が、既に定着されていますか?
まずはしっかりとデータを活用できている状態を目指し、その後に自社の目的に応じてデータ活用の一環として生成AIの活用を実施していく流れが望ましいです。
データを活用できる状態にどのように持っていけば良いかや、生成AIを活用する際の目的設定、また今回のソリューションのどのパターンをベースにしたら良いかの構想など、本件にご興味がございましたらぜひご相談ください。
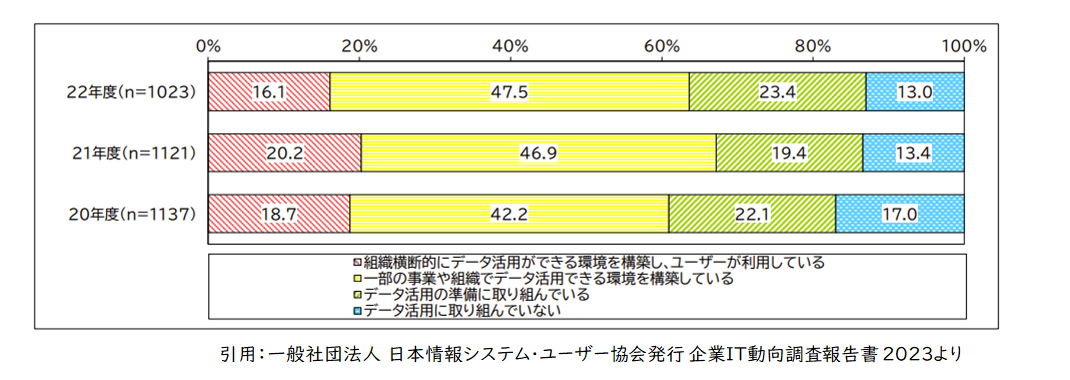
【図4】年度別 データ活用の取り組み状況
【出典】
図4:一般社団法人 日本情報システム・ユーザー協会発行 企業IT動向調査報告書 2023
https://juas.or.jp/cms/media/2023/07/JUAS_IT2023.pdf
関連サービス
#デジタル化戦略・ITマネジメント



 ソリューションに関する
ソリューションに関するオンライン相談問い合わせる メルマガ登録
最新情報をお届け! メルマガ登録
この記事の執筆者
-
 大谷 民雄DX・ERP事業部
大谷 民雄DX・ERP事業部
ディレクター -
 渡辺 健DX・ERP事業部
渡辺 健DX・ERP事業部
シニアマネージャー




職種別ソリューション



