労働力人口減少2030年の崖に備えよ
~第2回 DX化の推進~
この記事の要約
本記事は、労働力人口減少に備えるDX化の推進について解説した記事です。改革人財が取り組むべき背景として、2030年の崖、古いシステムの問題、情報発生元からの自動化、パッケージソフト活用、意思決定に必要なデータ定義のポイントを紹介しています。
この記事を読むとわかること
- 労働力人口2030年の崖とは何か
- DX化が遅れている企業がまず取り組むべきこと
- 情報発生元からの徹底的な自動化のポイント
- パッケージソフト活用と意思決定に必要なデータ定義のポイント
労働力人口2030年の崖とは
最初に第1回でお伝えした「労働力人口2030年の崖」について、簡単に振り返りたいと思います。
最初からお読みいただける方は第1回からお読みください。
日本の人口が減少していることを知らない方はいらっしゃらないかと思いますが、実は労働力人口(就業者数と求職者数を足した人数)はまだ減ってはいません。女性と65歳以上の労働力人口比率が増えることで横ばい、あるいは微増を維持してきました。
しかしながら、今後の予測も含めて人口ピラミッドを見ていただくと、第2次ベビーブーム世代(1971年~1974年生まれ)以降の年齢では、人口が減少し続けていることが見て取れます。第2次ベビーブーム世代がリタイアしてしまえば、最早労働力人口の減少を食い止めることは難しいと考えます。
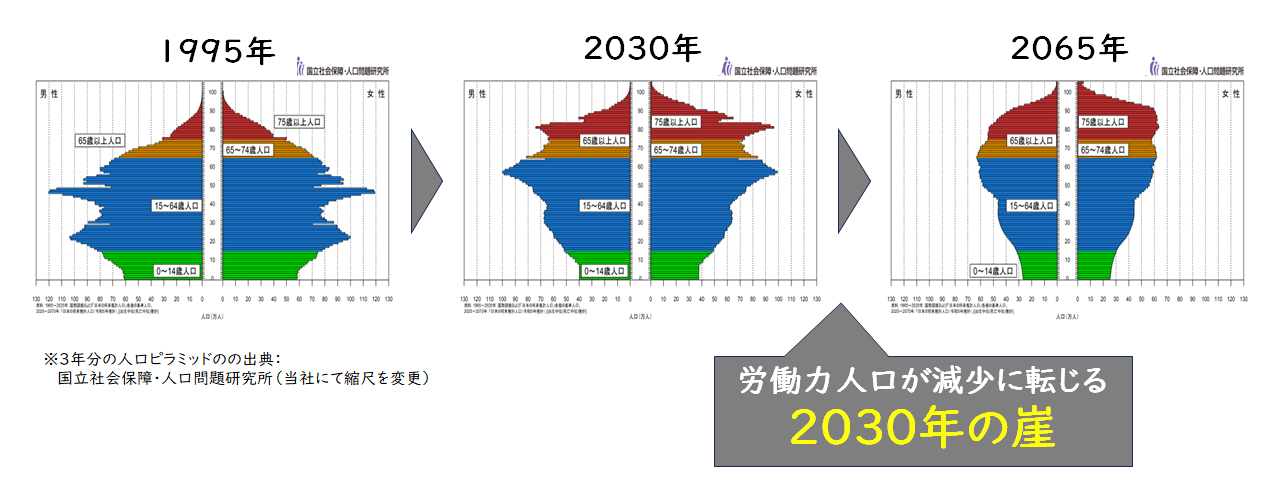
【図1】人口ピラミッドの推移
レイヤーズでは、労働力人口の維持から減少への変化点を、第2次ベビーブーム世代が60代に差しかかる2030年から始まると考えており、労働力人口減少期の始まりを「2030年の崖」と呼んでいます。
これまで全体の数として維持されてきた労働力人口が減少に転じるということは、当たり前ですが人手不足となり、リタイアしていく人数に比べて採用できる人数が少ないため、同じ業務のやり方を続けていくことができないことを意味します。2030年になるまでにいかに効率化を推進し続けられる業務の仕組みを構築できるかが重要であると考えます。
DX化が遅れているならまず取り組むべきはDX化
DX化の進捗状況は企業によって大きく差があります。
2020年前後に基幹システムを入れ替えた際に、ほとんど標準機能のままでクラウドのパッケージシステムに入れ替えており、基幹システム周辺のRPA化やAI-OCRの活用なども進んでいる企業もあれば、数十年前のシステムを人間がつなぎ合わせて使い続けており、DX化は課題だが簡単にはできないと悩んでおられる企業もあります。
例えば、ERP導入などはコストの高さに加え、費用対効果を出すのは一般的には難しいため、なかなか変えることができずに現在まできているという事情はよく分かります。
しかしながら、古いシステムが生産性を悪くしている問題を引き起こしているのであれば、なおさら人に余裕のある今のうちにこの状態から脱しておくことは非常に重要です。古いシステムが生産性を悪くしているのは、一般的には業務面だけではありません。古いシステムを維持すること自体にコストがかかっていることが多いと思われます。昔の技術ほど失われるのは早く、いずれ業務的にもシステム的にも現状を維持しきれない未来が来ることは想像に難くありません。まだ技術者がいる今のうちに手を付ける必要があるのではないでしょうか。
DX化といっても幅広いのですが、今回は全社の取引情報や経営管理情報を扱う仕組みの再構築を想定して、ポイントを3点述べたいと思います。
ポイント1:情報発生元からの徹底的な自動化に拘る
ポイント2:パッケージソフトをそのまま使うことに拘る
ポイント3:意思決定を支えるのに必要なデータに拘る
ポイント1:情報発生元からの徹底的な自動化に拘る
「徹底的な自動化」というと、理想としては当たり前だと感じられる方も多いことと思います。
自動処理になれば人間がやるよりも速くて正確で、しかも24時間処理し続けてくれますので、2030年を待たずして人手不足や高齢化は一部の企業に広がっているため、自動化に期待されている方は多いように見受けられます。
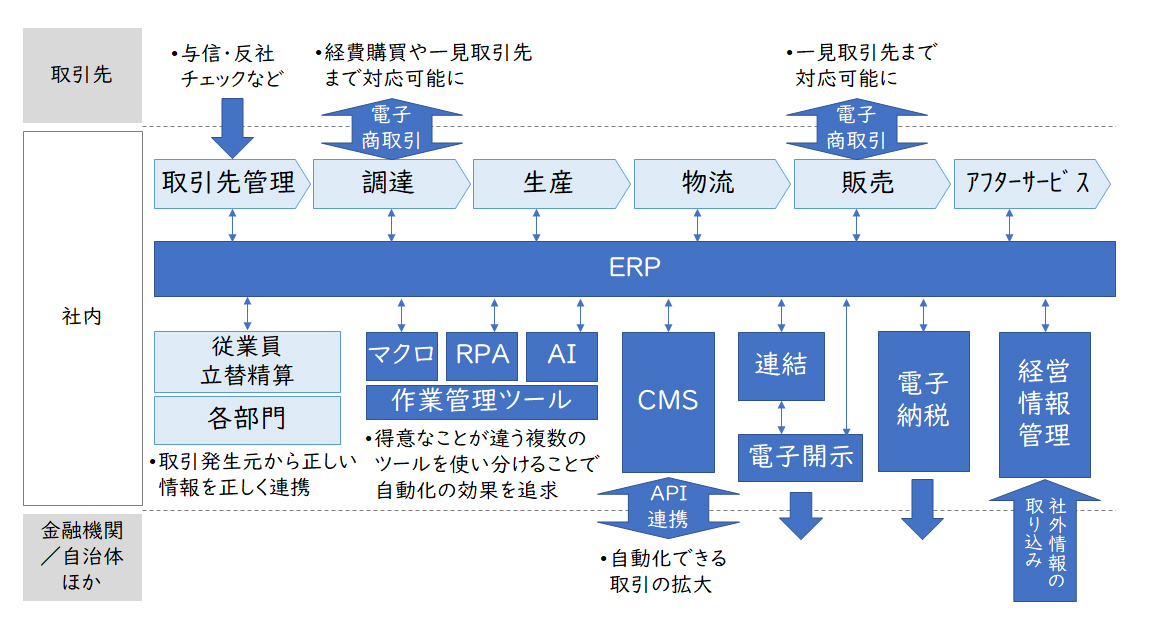
【図2】様々なDXツールの組み合わせで自動化を追求(イメージ)
一つ注意が必要なのは、現在のプロセスをそのまま自動化するのがよいということではないということです。多くの場合、業務は増築に増築を重ねた古い建物のように、過去の経緯を残した複雑な作りになっています。大企業であればさらに組織の壁、担当の壁が存在し、各部署や各人にとっての個別最適な増築を重ねているので、全社で見るとすでに使われていない空き部屋が存在したり、迷宮のような複雑な迂回をしたりしている場合もあります。
とあるお客様で、実際に決算で使われているExcelツールの分析をさせていただいたところ、マニュアルに書かれている手順とExcelツールの数式等、ロジックの60%が不要なものだったということがありました。処理としては必要な部分も単に数式で処理できるものなのに、人間が一つひとつ数字を拾って足し引きしていくという不思議なプロセスが作られていました。
自動化の推進にあたっては、全社の視点で情報の発生元とその情報を活用するアウトプットを特定し、その間をできるだけシンプルにつなぎなおす視点が必要です。実際にはERPなど市販のパッケージソフトウェアを使うことも多いと思いますが、そういった仕組みの組み合わせでいかにシンプルで、情報発生元からアウトプットまで途切れることなく自動で処理できる仕組みができるかを考えていくこととなります。
また、情報発生元からの自動化に拘ることを勧めるもう一つの理由は内部統制です。
未だ最終的に作られた帳票にハンコを押してJ-SOX用の証跡を作られる企業もありますが、効率化の観点からITACとシステムの処理が正確であることの証明、そしてITGCとシステムが適切に管理されていることから問題はないというこの2点の実質的な整備を進めることも極めて重要です。マニュアルコントロールであればそもそも人間がチェックをし、さらに内部統制のテストにも負荷がかかりますが、システムコントロールにしてしまえば、コントロールの実施は自動で内部統制のテストも最低限で済みます。
ポイント2:パッケージソフトをそのまま使うことに拘る
できるだけ速くDX化を進めるためには、パッケージソフトウェアをそのまま使うことは極めて重要です。Fit to Standardという言葉で皆様よくご存じかとは思いますが、具体的な話になるとどこがポイントなのか理解が分かれていることもあるようですので、ユーザー部門の目線でお伝えしたいと思います。
まず、「そのまま使う」とはどういうことかですが、極端にいえば設定のみで使い始めることです。何が設定で、何が開発かわかりづらい場合は、システムベンダーに作ってもらうものが開発だと考えてください。設定の中にはユーザーが自分でできるものと、システムベンダーに設定してもらうものがありますが、デモンストレーションやプロトタイプなどで実際に動いている様子が見られるものは、設定で実現できる範囲です。
インタフェースの口を最初から持っているかどうかの違いはありますが、開発がどうしても必要になるのはインタフェース(システム間データ連携)であり、先に述べた徹底的な自動化にもつながる部分ですので、インタフェース開発はむしろ拘って開発すべき部分と考えます。
当然、パッケージソフトウェアをそのまま使おうとすると業務プロセスは影響を受けますが、この時既存のやり方を残して最低限新システムに合わせようとすると、先ほど述べたような増築を繰り返した家のようになってしまいますので、業務プロセスは一度ゼロリセットして、新システムに合わせた効率的なやり方を考える必要があります。
なお機能によりますが、会計システムなどの法制度対応が頻繁に起きることが想定できる機能は、パッケージベンダー側のバージョンアップで対応してもらえるものが理想です。インタフェースに影響が出る可能性はゼロではありませんので、全てお任せで済むとはいえませんが、それでも自社独自で法制度対応を考えるなどに比べて負荷が低いのは間違いありません。労働人口減少の未来を想定した時に、将来にわたるバージョンアップの負荷というのも考慮すべきポイントの一つになると考えます。
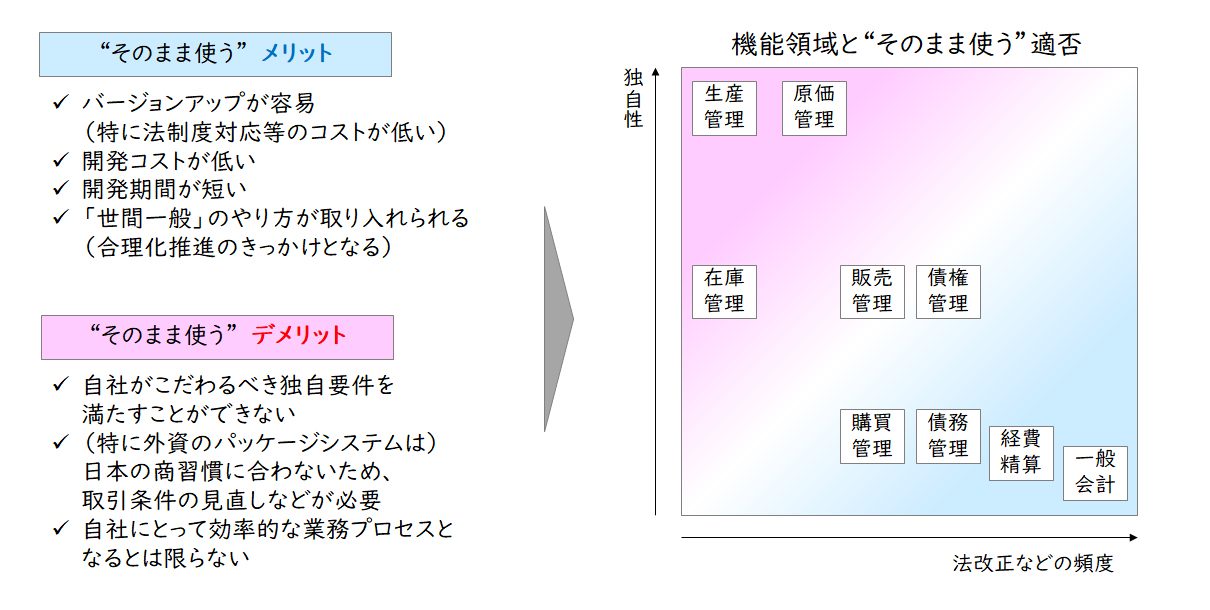
【図3】パッケージソフトを“そのまま使う”効果の高い領域
ポイント3:意思決定を支えるのに必要なデータに拘る
もう一つ拘っていただきたいのはデータです。
社内のどこかには必要な情報はあるんだけど…という状態では使用に耐えません。
かといって何でも細かい粒度で集約していつでも使えるようにするというのも、これだけ膨大にデータが溢れている現在、あまりよい手段であるとは思えません。全社視点で必要なデータとは何かを定義することが重要です。特に絶対に保存しないといけないものを落とすことはあまりありませんので、なくても済んでしまうがよい意思決定をするために必要なデータは何かをよく分析・議論することが重要です。
次に、必要なデータが決まりましたら、その粒度と鮮度を定義します。
例えば、売上高という情報が定義された時に、それを受注番号単位で持つのか、納品/サービス提供単位で持つのか、部門ごとに持つのか、製品区分/サービス区分ごとに持つのかを考えます。また、鮮度としてはリアルタイムに必要なのか、毎日前日の分が見られればよいのか、1か月まとめて実績が見られればよいのか、これらの情報を誰がいつどんな判断をするために使うのかを想定して定義していきます。
加えて、検討が必要なのは予測情報であり、売上高実績の用途から実績として必要な粒度と鮮度を定義したうえで、それとは別に売上の予測情報、あるいは利益などまた別の予測情報を作るうえで、変数を変えるなどのために分けて持つべき単位というのがあるはずですので、この視点での検討も重要です。
必要なデータとその粒度・鮮度が決まりましたら、それを新システムの中でどのように実現するかを検討していきます。意思決定に必要な情報は、いくら想定しても増えていくことは常ですので、ある程度の拡張性も想定しておくことが望ましいでしょう。
ここまでご精読いただきありがとうございました。
次回本シリーズの第3回目では、2030年の崖を乗り越えるための取り組みの3つ目として、一度効率的に変更した業務を、効率的な状態で維持し続けていく方法についてご紹介します。
【引用文献】
・【図1】:国立社会保障・人口問題研究所「3年分の人口ピラミッドの出典」
オンライン相談問い合わせる メルマガ登録
最新情報をお届け! メルマガ登録
この記事の執筆者
-
 青柳 智子経営管理事業部
青柳 智子経営管理事業部
マネージングディレクター -
 増田 凪紗経営管理事業部
増田 凪紗経営管理事業部
シニアコンサルタント






職種別ソリューション



